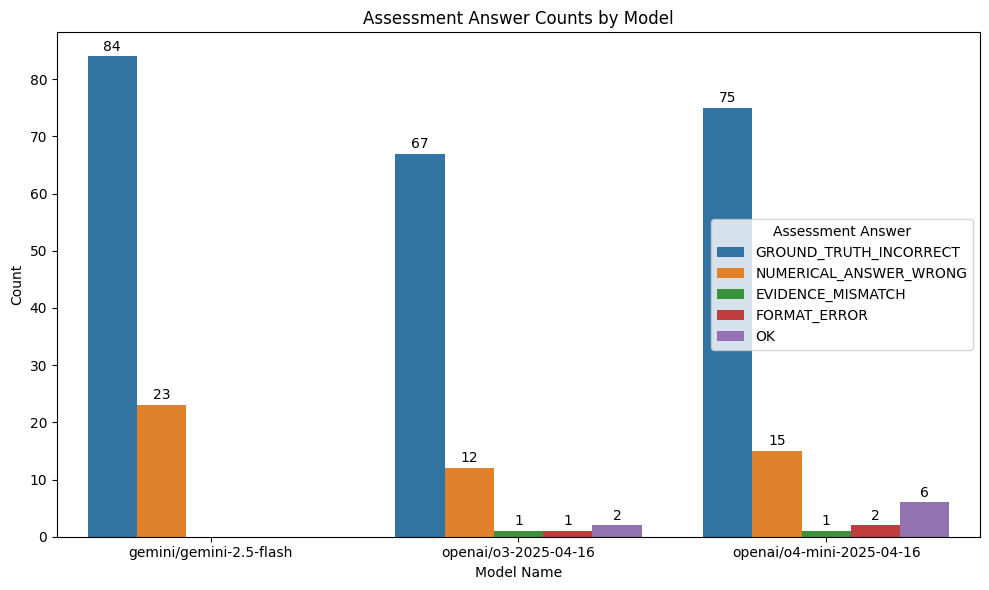
| 0 |
None |
[PRE] entergy corporation and subsidiaries management's financial ... |
| Row | 2009 net revenue | volume/weather | retail electric price ... |
what was the difference in net revenue between 2009 and 2010? |
Single_ETR/2011/page_22.pdf-3 |
entergy corporation and subsidiaries management's financial discus... |
the volume/weather variance is primarily due to an increase of 836... |
{'amount ( in millions )': {'2009 net revenue': 4694.0, 'volume/we... |
['what was the difference in net revenue between 2009 and 2010?', ... |
[357, 4694, 7.61%] |
... |
[357.0, 4694.0, 0.07605] |
[False, False, False] |
3 |
False |
False |
False |
357.00000 |
subtract(2010 net revenue, 2009 net revenue) |
357.0 |
✔️ [1.000] |
| 1 |
Q1: what was the difference in net revenue between 2009 and 2010?\... |
[PRE] entergy corporation and subsidiaries management's financial ... |
| Row | 2009 net revenue | volume/weather | retail electric price ... |
and the specific value for 2009 again? |
Single_ETR/2011/page_22.pdf-3 |
entergy corporation and subsidiaries management's financial discus... |
the volume/weather variance is primarily due to an increase of 836... |
{'amount ( in millions )': {'2009 net revenue': 4694.0, 'volume/we... |
['what was the difference in net revenue between 2009 and 2010?', ... |
[357, 4694, 7.61%] |
... |
[357.0, 4694.0, 0.07605] |
[False, False, False] |
3 |
False |
False |
False |
4694.00000 |
4694.0 |
4694.0 |
✔️ [1.000] |
| 2 |
Q1: what was the difference in net revenue between 2009 and 2010?\... |
[PRE] entergy corporation and subsidiaries management's financial ... |
| Row | 2009 net revenue | volume/weather | retail electric price ... |
so what was the percentage change during this time? |
Single_ETR/2011/page_22.pdf-3 |
entergy corporation and subsidiaries management's financial discus... |
the volume/weather variance is primarily due to an increase of 836... |
{'amount ( in millions )': {'2009 net revenue': 4694.0, 'volume/we... |
['what was the difference in net revenue between 2009 and 2010?', ... |
[357, 4694, 7.61%] |
... |
[357.0, 4694.0, 0.07605] |
[False, False, False] |
3 |
False |
False |
False |
0.07605 |
subtract(5051.0, 4694.0), divide(#0, 4694.0), multiply(#1, const_100) |
7.61 |
|
| 3 |
None |
[PRE] entergy new orleans , inc . management's financial discussio... |
| Row | 2003 net revenue | base rates | volume/weather | 2004 defe... |
what was the net revenue in 2004? |
Single_ETR/2004/page_258.pdf-4 |
entergy new orleans , inc . management's financial discussion and ... |
the increase in base rates was effective june 2003 . the rate incr... |
{'( in millions )': {'2003 net revenue': 208.3, 'base rates': 10.6... |
[what was the net revenue in 2004?, what was the net revenue in 20... |
[239.0, 208.3, 30.7, 14.7%] |
... |
[239.0, 208.3, 30.7, 0.14738] |
[False, False, False, False] |
4 |
False |
False |
False |
239.00000 |
None |
239.0 |
✔️ [1.000] |
| 4 |
Q1: what was the net revenue in 2004?\nA1: 239.0 |
[PRE] entergy new orleans , inc . management's financial discussio... |
| Row | 2003 net revenue | base rates | volume/weather | 2004 defe... |
what was the net revenue in 2003? |
Single_ETR/2004/page_258.pdf-4 |
entergy new orleans , inc . management's financial discussion and ... |
the increase in base rates was effective june 2003 . the rate incr... |
{'( in millions )': {'2003 net revenue': 208.3, 'base rates': 10.6... |
[what was the net revenue in 2004?, what was the net revenue in 20... |
[239.0, 208.3, 30.7, 14.7%] |
... |
[239.0, 208.3, 30.7, 0.14738] |
[False, False, False, False] |
4 |
False |
False |
False |
208.30000 |
None |
208.3 |
✔️ [1.000] |
| 5 |
Q1: what was the net revenue in 2004?\nA1: 239.0\nQ2: what was the... |
[PRE] entergy new orleans , inc . management's financial discussio... |
| Row | 2003 net revenue | base rates | volume/weather | 2004 defe... |
what was the change in value? |
Single_ETR/2004/page_258.pdf-4 |
entergy new orleans , inc . management's financial discussion and ... |
the increase in base rates was effective june 2003 . the rate incr... |
{'( in millions )': {'2003 net revenue': 208.3, 'base rates': 10.6... |
[what was the net revenue in 2004?, what was the net revenue in 20... |
[239.0, 208.3, 30.7, 14.7%] |
... |
[239.0, 208.3, 30.7, 0.14738] |
[False, False, False, False] |
4 |
False |
False |
False |
30.70000 |
subtract(239.0, 208.3) |
30.7 |
✔️ [1.000] |
| 6 |
Q1: what was the net revenue in 2004? A1: 239.0 Q2: what was the n... |
[PRE] entergy new orleans , inc . management's financial discussio... |
| Row | 2003 net revenue | base rates | volume/weather | 2004 defe... |
what is the percent change? |
Single_ETR/2004/page_258.pdf-4 |
entergy new orleans , inc . management's financial discussion and ... |
the increase in base rates was effective june 2003 . the rate incr... |
{'( in millions )': {'2003 net revenue': 208.3, 'base rates': 10.6... |
[what was the net revenue in 2004?, what was the net revenue in 20... |
[239.0, 208.3, 30.7, 14.7%] |
... |
[239.0, 208.3, 30.7, 0.14738] |
[False, False, False, False] |
4 |
False |
False |
False |
0.14738 |
subtract(239.0, 208.3), divide(#0, 208.3), multiply(#1, 100) |
14.72 |
|
| 7 |
None |
[PRE] nike , inc . notes to consolidated financial statements 2014... |
| Row | severance and related costs | cash payments | non-cash sto... |
what was the value of the sale of the starter brand? |
Single_NKE/2009/page_81.pdf-1 |
nike , inc . notes to consolidated financial statements 2014 ( con... |
the accrual balance as of may 31 , 2009 will be relieved throughou... |
{'$ 2014': {'severance and related costs': 195.0, 'cash payments':... |
['what was the value of the sale of the starter brand?', 'what was... |
[60.0, 28.6, 31.4, 91%] |
... |
[60.0, 28.6, 31.4, 0.91083] |
[False, False, False, False] |
4 |
False |
False |
False |
60.00000 |
None |
60.0 |
✔️ [1.000] |
| 8 |
Q1: what was the value of the sale of the starter brand?\nA1: 60.0 |
[PRE] nike , inc . notes to consolidated financial statements 2014... |
| Row | severance and related costs | cash payments | non-cash sto... |
what was the gain resulting from the sale? |
Single_NKE/2009/page_81.pdf-1 |
nike , inc . notes to consolidated financial statements 2014 ( con... |
the accrual balance as of may 31 , 2009 will be relieved throughou... |
{'$ 2014': {'severance and related costs': 195.0, 'cash payments':... |
['what was the value of the sale of the starter brand?', 'what was... |
[60.0, 28.6, 31.4, 91%] |
... |
[60.0, 28.6, 31.4, 0.91083] |
[False, False, False, False] |
4 |
False |
False |
False |
28.60000 |
None |
28.6 |
✔️ [1.000] |
| 9 |
Q1: what was the value of the sale of the starter brand?\nA1: 60.0... |
[PRE] nike , inc . notes to consolidated financial statements 2014... |
| Row | severance and related costs | cash payments | non-cash sto... |
what was the change in value? |
Single_NKE/2009/page_81.pdf-1 |
nike , inc . notes to consolidated financial statements 2014 ( con... |
the accrual balance as of may 31 , 2009 will be relieved throughou... |
{'$ 2014': {'severance and related costs': 195.0, 'cash payments':... |
['what was the value of the sale of the starter brand?', 'what was... |
[60.0, 28.6, 31.4, 91%] |
... |
[60.0, 28.6, 31.4, 0.91083] |
[False, False, False, False] |
4 |
False |
False |
False |
31.40000 |
subtract(60.0, 28.6) |
31.4 |
✔️ [1.000] |
 ,
,