Optimzing DSPy programs for ConvFinQA
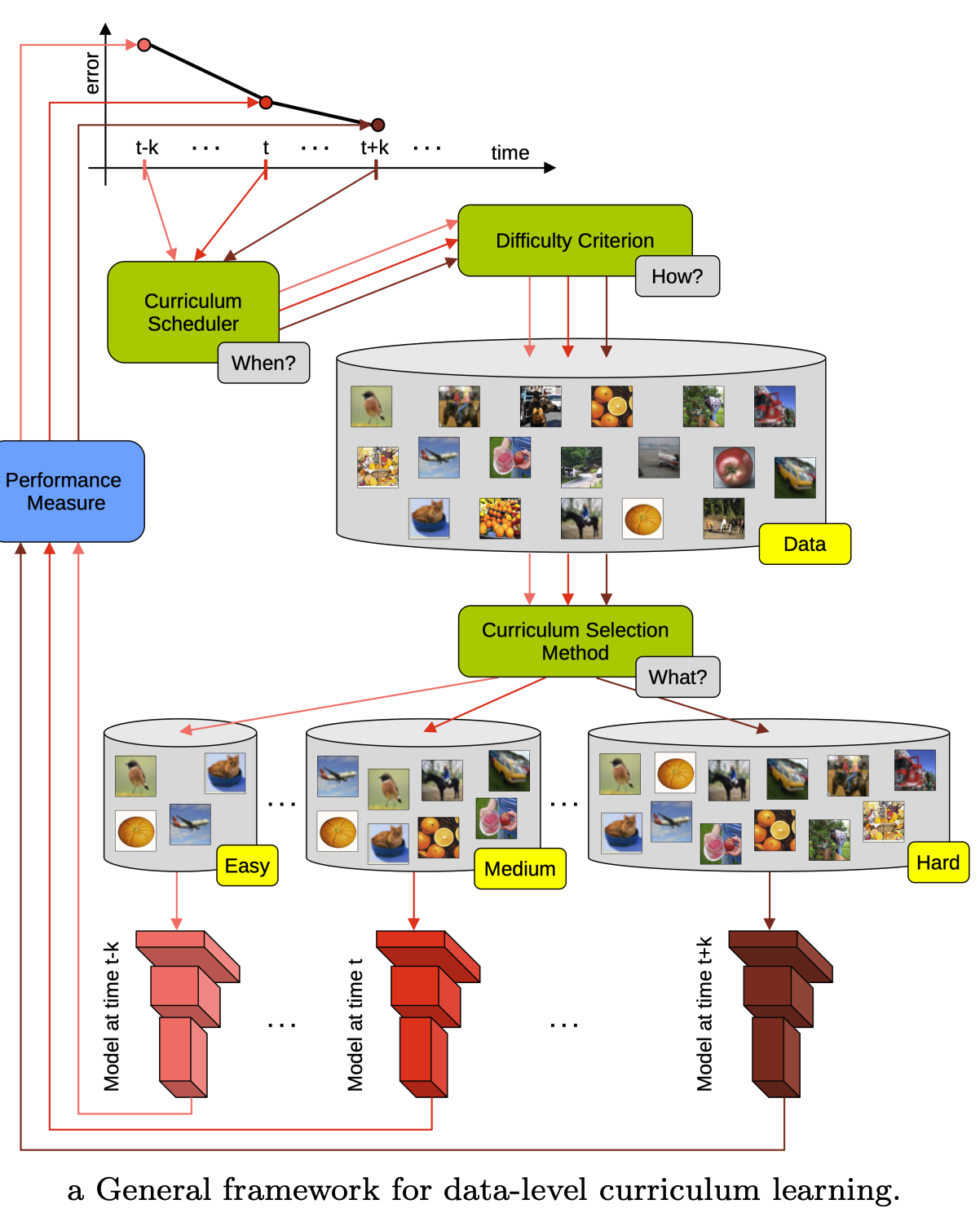
Curriculum design for ConvFinQA, paving the way to program optimization
Mapping ConvFinQA and crafting a curriculum for financial QA
Intersection of steganography x neural networks, with API credits as a reward!
Moar GPU puzzles with slide-n-sum pooling, tile-flipping convs & warp-speed scans
Learning GPU programming fundamentals through hands-on Mojo implementations
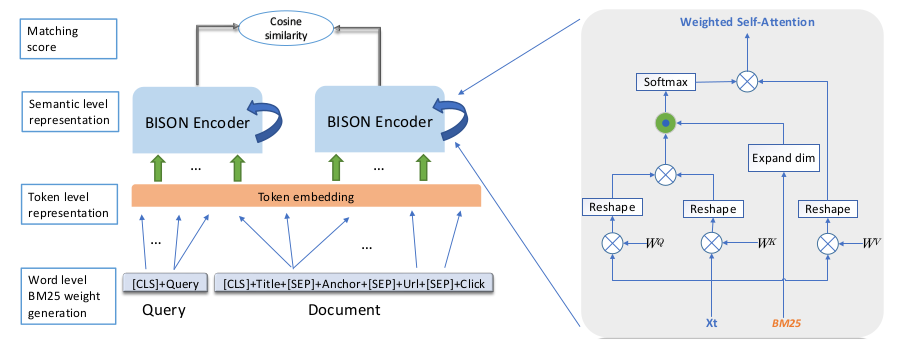
A new framework for information retrieval from documents
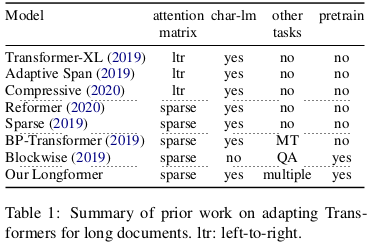
Transformers for loooong documents
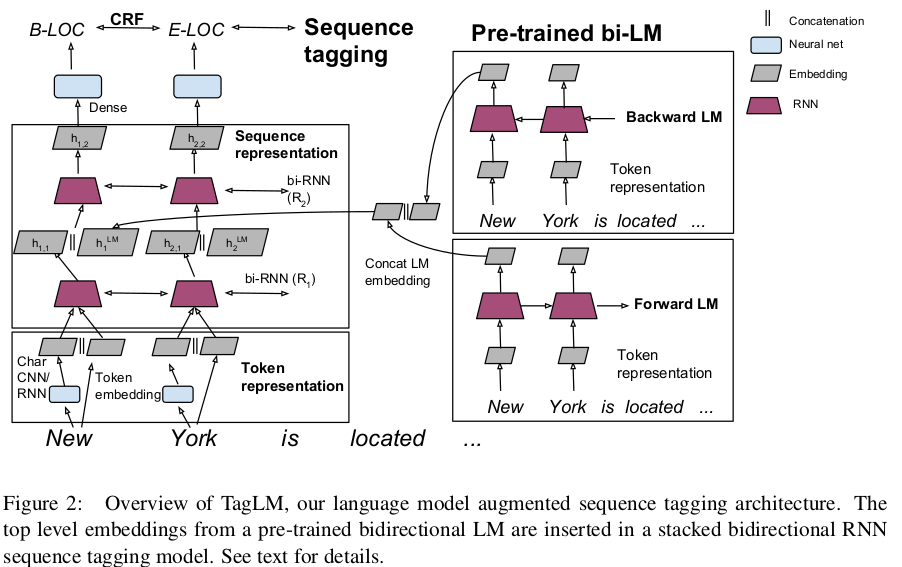
Bidirectional LM embeddings for sequence tagging
Measure the amount of information stored in a model
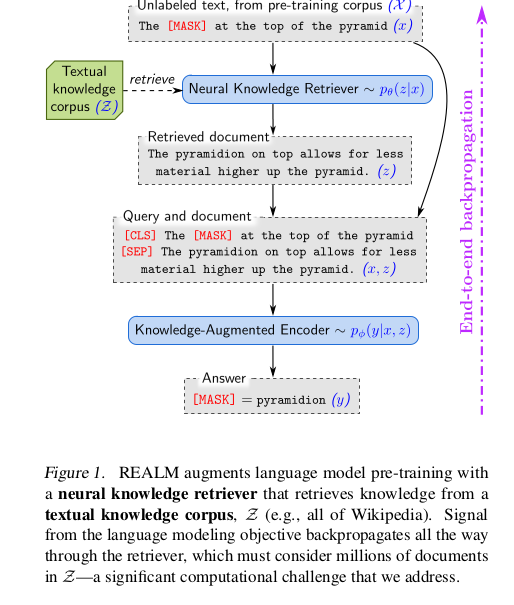
A better Q&A system based on knowledge retrieval
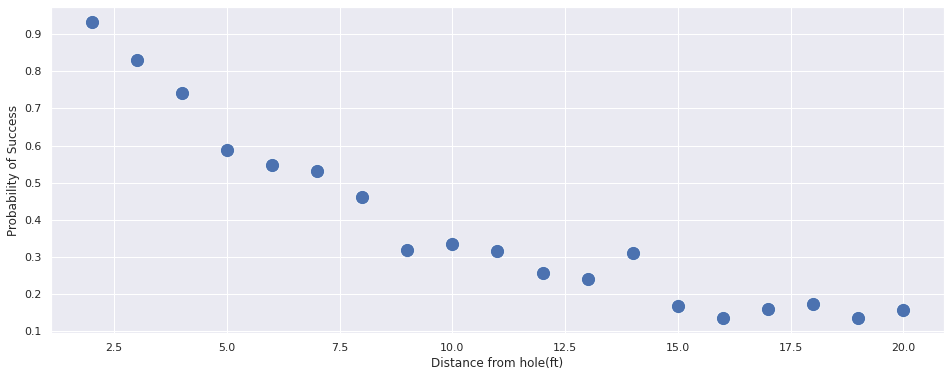
Are you the next Tiger Woods?
First post



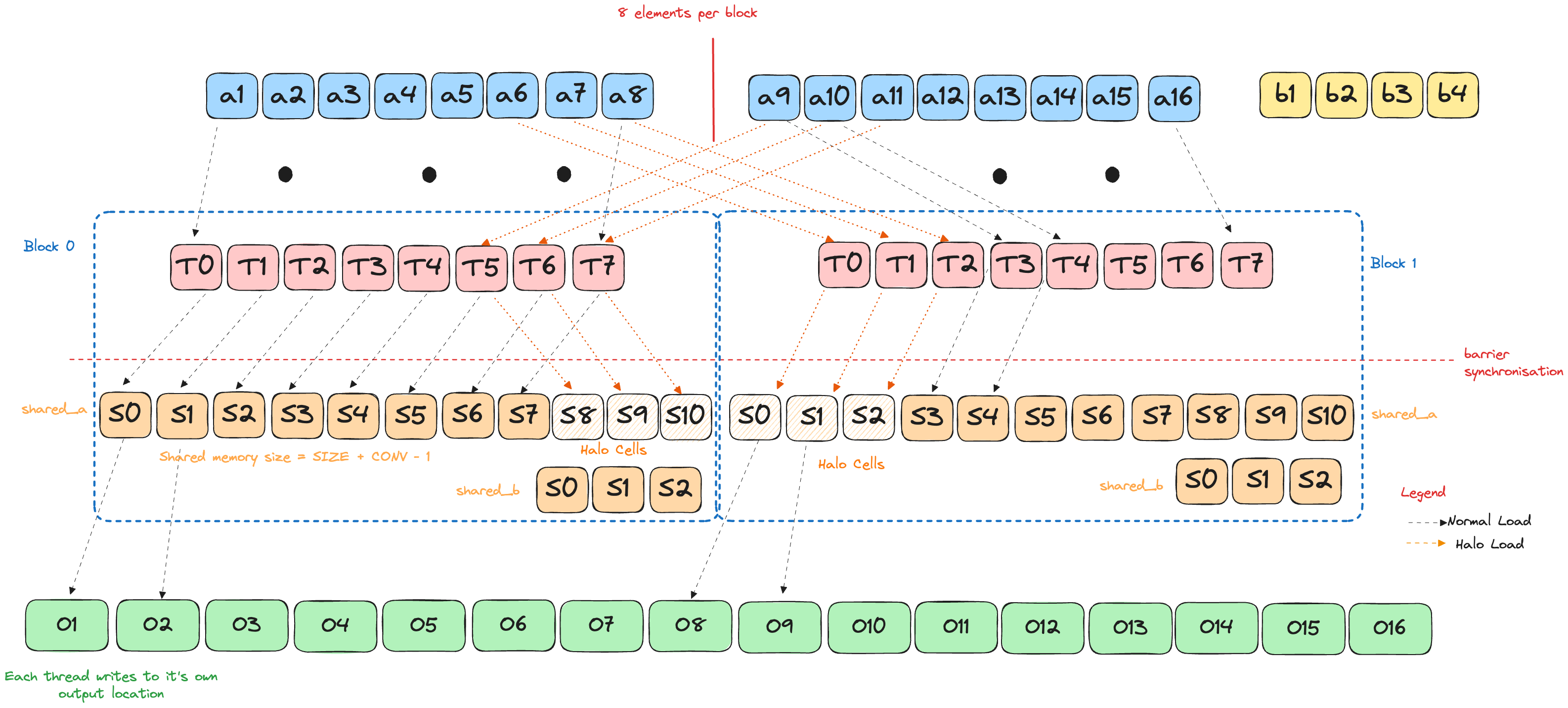
![Source: FlashAttention [5]. Metrics shown are for an NVIDIA A100 GPU.](posts/mojo_gpu_puzzles/memory_hierachy_fa.png)